参考资料
- Understanding Random Forests Classifiers in Python: //www.datacamp.com/community/tutorials/random-forests-classifier-python
- Random Forest Algorithm with Python and Scikit-Learn: //stackabuse.com/random-forest-algorithm-with-python-and-scikit-learn/
- Random Forest in Python: //towardsdatascience.com/random-forest-in-python-24d0893d51c0
随机森林(RandomForest)算法
随机森林属于集成学习(Ensemble Learning)的一类算法,结合了多种相同类型的算法,即多个决策树,从而形成了一个随机森林树。
随即森林是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。上世纪八十年代Breiman等人发明分类树的算法(Breiman et al. 1984),通过反复二分数据进行分类或回归,计算量大大降低。2001年Breiman把分类树组合成随机森林(Breiman 2001a),即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元公线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用(Breiman 2001b),被誉为当前最好的算法之一(Iverson et al. 2008)。
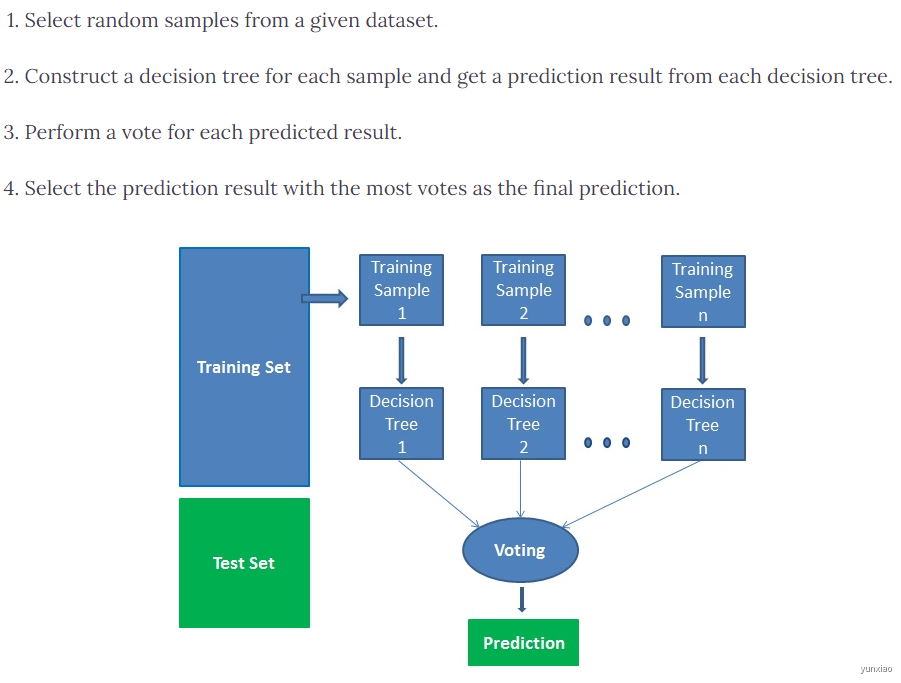
随机森林工作原理
随机森林优缺点
优点
- 准确度高
- 没有过拟合问题
- 可用于分类和回归问题
- 可以处理缺失值,一是用中位数代替连续变量,二是计算缺失值的近似加权平均值;也可用于没有归一化的问题
缺点
- 速度慢
- 与决策树相比较难解释
随即森林与决策树
- 随机森林是一组多决策树。
- 深度决策树可能会出现过拟合,但随机森林通过在随机子集上创建树来防止过拟合。
- 决策树的计算速度更快。
- 随机森林很难解释,而决策树很容易解释,可以转换为规则。
利用Scikit-learn实现随即森林的分析
随机森林通过 RandomForestClassifier实现分类问题
随机森林通过 RandomForestRegressor 实现回归问题
1 | from sklearn.ensemble import RandomForestClassifier |
随机森林解决回归问题
- 问题
根据汽油税(美分),人均收入(美元),已铺设的高速公路(以英里为单位)和驾驶执照人口与汽油税的比例,来预测美国48个州的汽油消耗量(百万加仑)。
数据链接:https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
- 读入数据
1 | dataset = pd.read_csv('petrol_consumption.csv') |
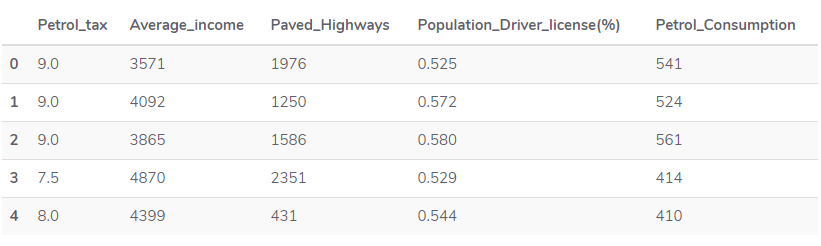
- 数据前处理
提取’attributes’ 和 ‘label’; 拆分测试数据和训练数据集
注意:random_state 设置随机数种子,以保证多次运行的结果相同
1 | X = dataset.iloc[:, 0:4].values |
- 数据归一化(Feature Scaling)
1 | # Feature Scaling |
- 训练模型
注意:重要参数 n_estimators , 表示随机森林树的数目
1 | from sklearn.ensemble import RandomForestRegressor |
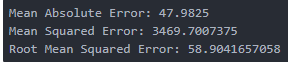
- 模型评估
1 | from sklearn import metrics |
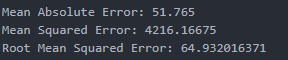
当参数改为200时,模型评估结果提升了n_estimators=200
随机森林解决分类问题
- 问题:根据四个属性(即图像小波变换后的图像的方差,偏度,熵和图像的弯曲度)来预测银行纸币是否真实
- 读入数据
1 | import pandas as pd |
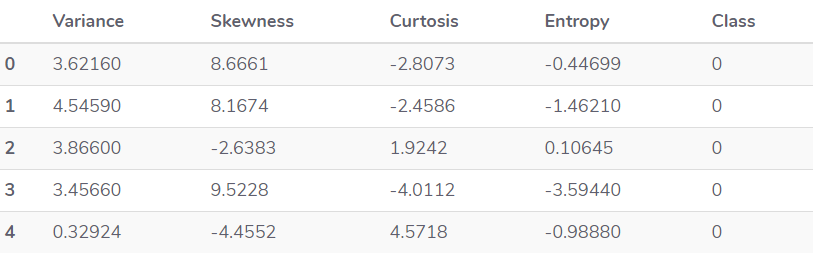
- 数据预处理
1 | X = dataset.iloc[:, 0:4].values |
拆分测试数据和训练数据
1 | from sklearn.model_selection import train_test_split |
- 归一化
1 | # Feature Scaling |
- 训练模型
1 | from sklearn.ensemble import RandomForestClassifier |
- 模型评估
1 | from sklearn.metrics import classification_report, confusion_matrix, accuracy_score |
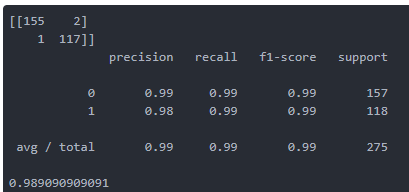
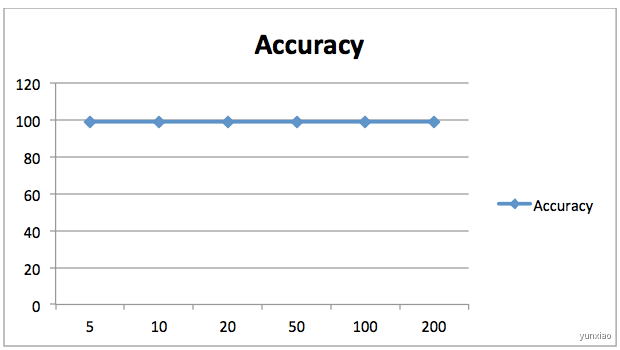
这里将n_estimators=20 改为200时,结果并没有明显改变