概述
正则表达式(Regular Expression)在字符串模式匹配,在字符串搜索和替换中展现强大的功能。
常用的正则表达式语法我将其总结为7类:
先看一个概括的整理

字符类**
\w: 匹配数字和字符.: 匹配除换行符 \n 之外的任何单字符[a-z]和[A-Z]:匹配从a到z或者A到Z的任意字符[0-9]: 匹配0到9的任意数字
数值类
\d:匹配数字
分隔符类
\s: 匹配white space(包括空格、tab等)
定位类:在字符类和数值类前面
^: 字符开头$:字符结尾\b: 单词结界符
定量类,包含数值型和特殊符类,放在字符类和数值类后面
- 数值型:{}, 大括号里加数字
*: 0次或多次+: 1次或多次?: 0或1次
逻辑关系类
[]:表示逻辑关系或,比如[abc]表示a或者b或c(|): () 和 | 结合也表示逻辑关系或
分组类
**()**: 用于分组
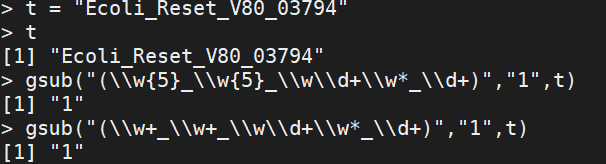
示例
R语言可以结合gsub使用正则匹配语法
gsub语法: gsub("old value 或 pattern","new value",data)