数据不平衡的分类问题
机器学习中数据不平衡的分类问题很常见,如医学中的疾病诊断,患病的数据比例通常小于正常的;还有欺诈识别,垃圾邮件检测,异常值的检测等。而极端的数据不平衡通常会影响模型预测的准确性和泛化性能。
这里介绍几种处理不平衡数据的计算方法:
- Oversample and downsample
- Generating synthetic data, eg. SMOTE, ADASYN
- GAN
方法
1. oversample and downsample
一种简单直接的方法是随机重采样 (randomly resample),包括oversample和downsample。Oversample 即对少数组别重复取样,downsample 即从多数类中删除示例。但是,同时要注意Oversample可能导致某些模型过度拟合。downsample可能导致丢失对模型非常宝贵的信息。
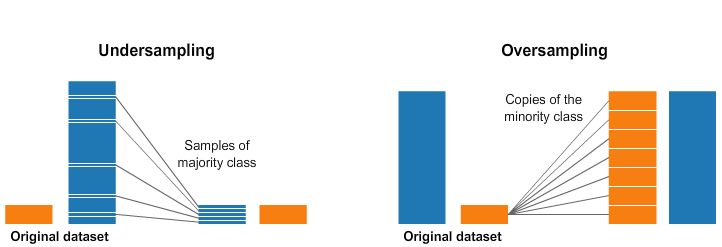
可以利用python中imbalanced-learn package实现,如
1 | ## install and import package |
这里定义产生一个极度不平衡的数据(1:100的二分类问题),以oversample为例看一下具体实现的过程:
1 | # define dataset |
2. SMOTE
另一种处理数据不平衡的方法是可以从现有示例中合成新示例。如 SMOTE (Synthetic Minority Oversampling Technique) 即合成少数组别的过采样技术。相对于oversample直接对少数类群中复制示例,SMOTE是根据少数类别的数据产生了新的数据,属于数据增强(data augmentation )的一种方法。它的工作原理是选择特征空间中接近的示例,在特征空间中的示例之间绘制一条线,并在该线的某个点处绘制一个新样本。具体来说,首先从少数类中随机选择一个例子,然后找到这个例子的k个最近的邻值(通常是k=5)。随机选择一个邻值 ,并在特征空间中两个例子之间随机选择一个点,创建一个合成例子。
也可以通过python中imbalanced-learn package实现:
1 | ## import SMOTE package |
3. ADASYN
另一种oversample也是通过合成新样本的方法是ADASYN(Adaptive Synthetic Sampling)。它是通过生成与示例密度成反比的合成数据。即该方法在特征空间中少数示例密度低的区域生成更多合成示例,而在密度高的区域生成更少或不生成合成示例。
实现方法还可以通过python中imbalanced-learn package
1 | ## import ADASYN package |
4. GAN
最后介绍一种较新的方法—GAN (Generative Adversarial Networks) ,即生成对抗网络。其最初是为了从对抗训练过程中生成图像而发明的,是基于深度学习的一种数据增强方法。 GAN 由两个组件组成,一个生成器和一个判别器。生成器试图生成与真实数据相似的数据,而鉴别器试图区分真实数据和生成的数据,GAN 的训练基于这两个组件之间的对抗性游戏。GAN同样也可以用于解决数据不平衡的问题上,如DCGAN(DOI: 10.23919/ChiCC.2018.8483334)用深度卷积网络实现GAN; SDGAN (DOI: 10.1109/TASE.2020.2967415), ACGAN(arXiv:1610.09585v4)等模型 。
参考
- https://github.com/scikit-learn-contrib/imbalanced-learn
https://imbalanced-learn.org/stable/user_guide.html#user-guide
- https://arxiv.org/abs/1106.1813
- https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
- https://ieeexplore.ieee.org/abstract/document/9411996
- https://onlinelibrary.wiley.com/doi/10.1002/sam.11570?af=R
- https://www.sciencedirect.com/science/article/pii/S1877050918314364