SVM 简介
SVM(Support Vector Machines)支持向量机是机器学习中的一种分类算法,属于监督式学习,也可以同时用于分类和回归问题。SVM的核心思想是找到最大的边际超平面,以最大程度地将数据集划分为类。
SVM原理
术语
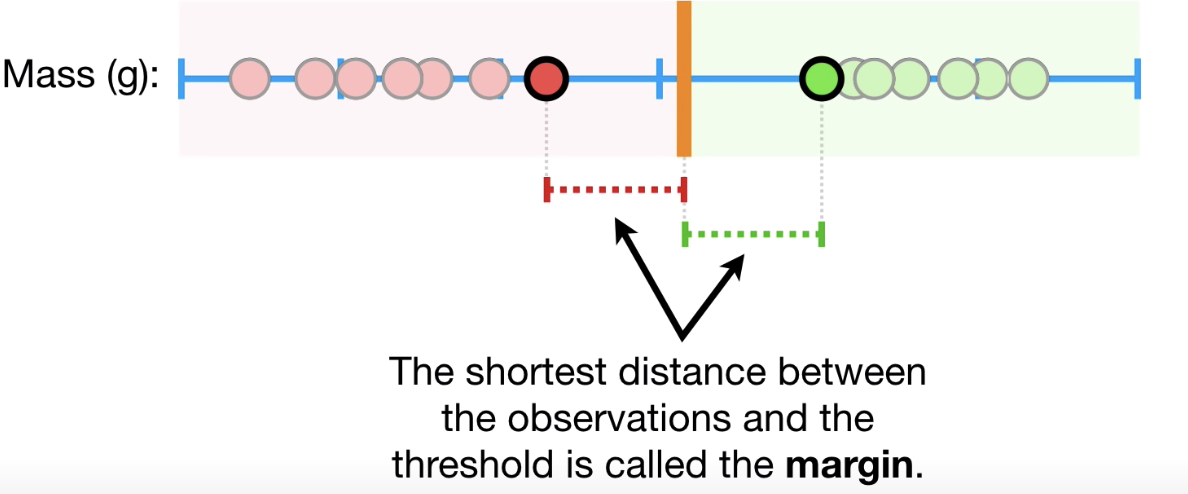
Margin
边距是最接近的分类点上的两条线之间的间隙。 这是从线到支持向量或最接近点的垂直距离来计算的。 如果两个类之间的边距较大,则认为是良好的边距,较小的边距是较差的边距
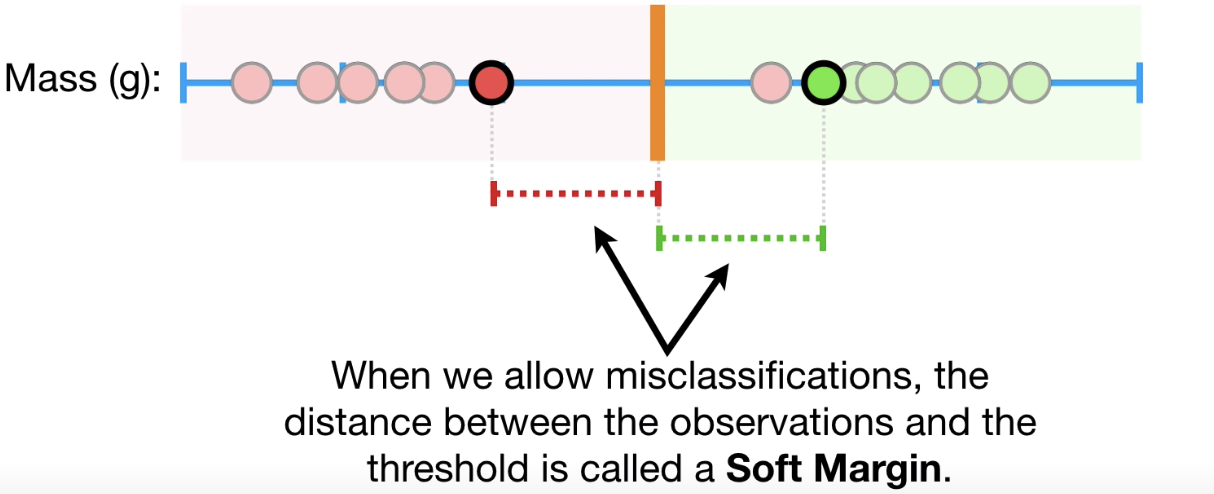
Soft Margin
允许错误分类,这时观测值和阈值间的距离也称作Soft Margin。使用Cross Validation确定在 Soft Margin错误分类的个数,从而得到最好的分类模型。
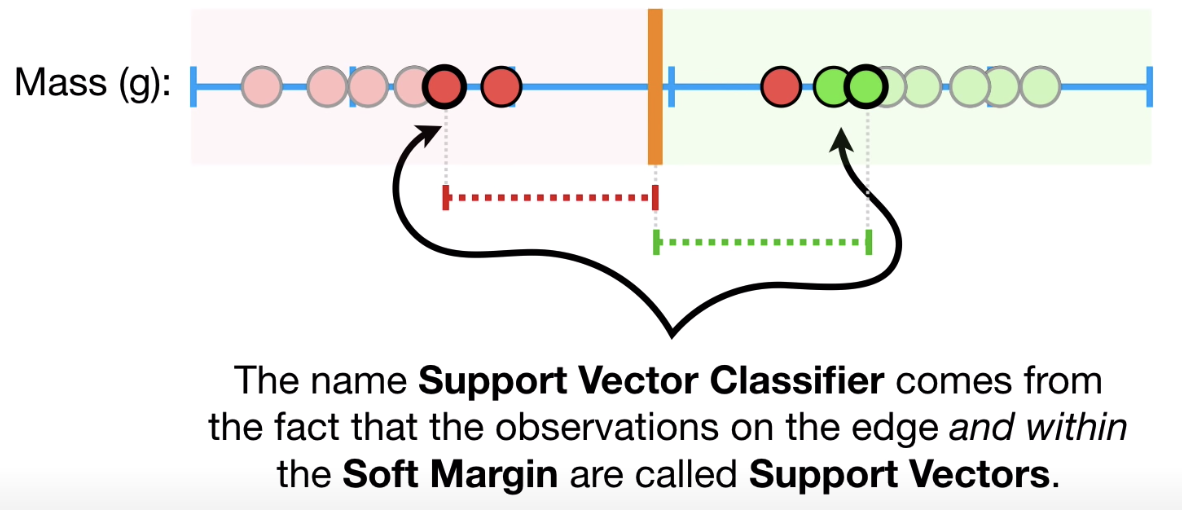
支持向量(Support Vectors)
支持向量是最靠近超平面的数据点。 这些点将通过计算边距更好地定义分隔线。 这些点与分类器的构建更相关
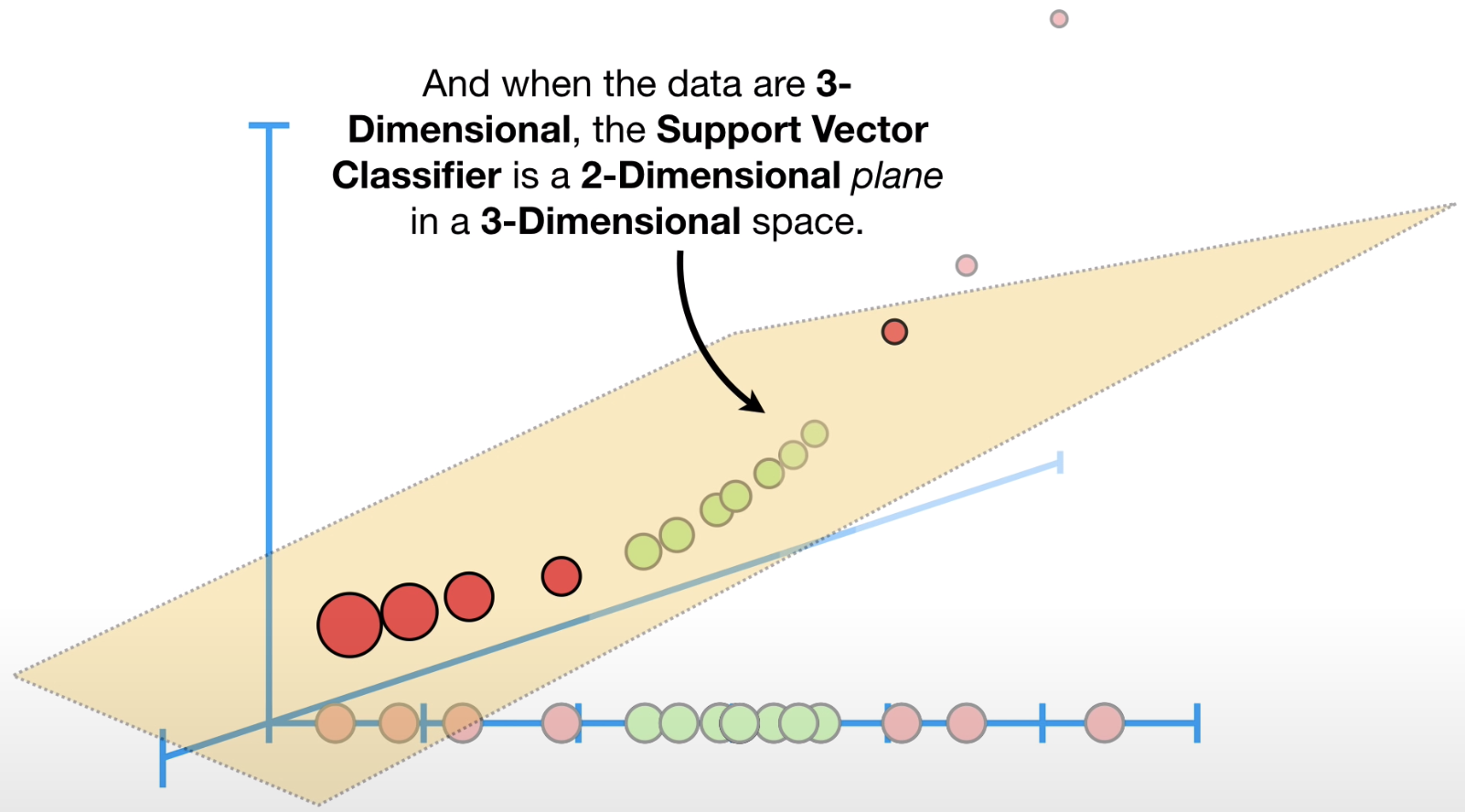
当处理的数据是一维时,Support Vector Classifier 是一个单独点;当处理的数据是二维时,Support Vector Classifier是一条线(如下图2-D);当处理的数据是三维时,Support Vector Classifier 是一个超平面(hyperplane)(如下图3-D)
图2-D:
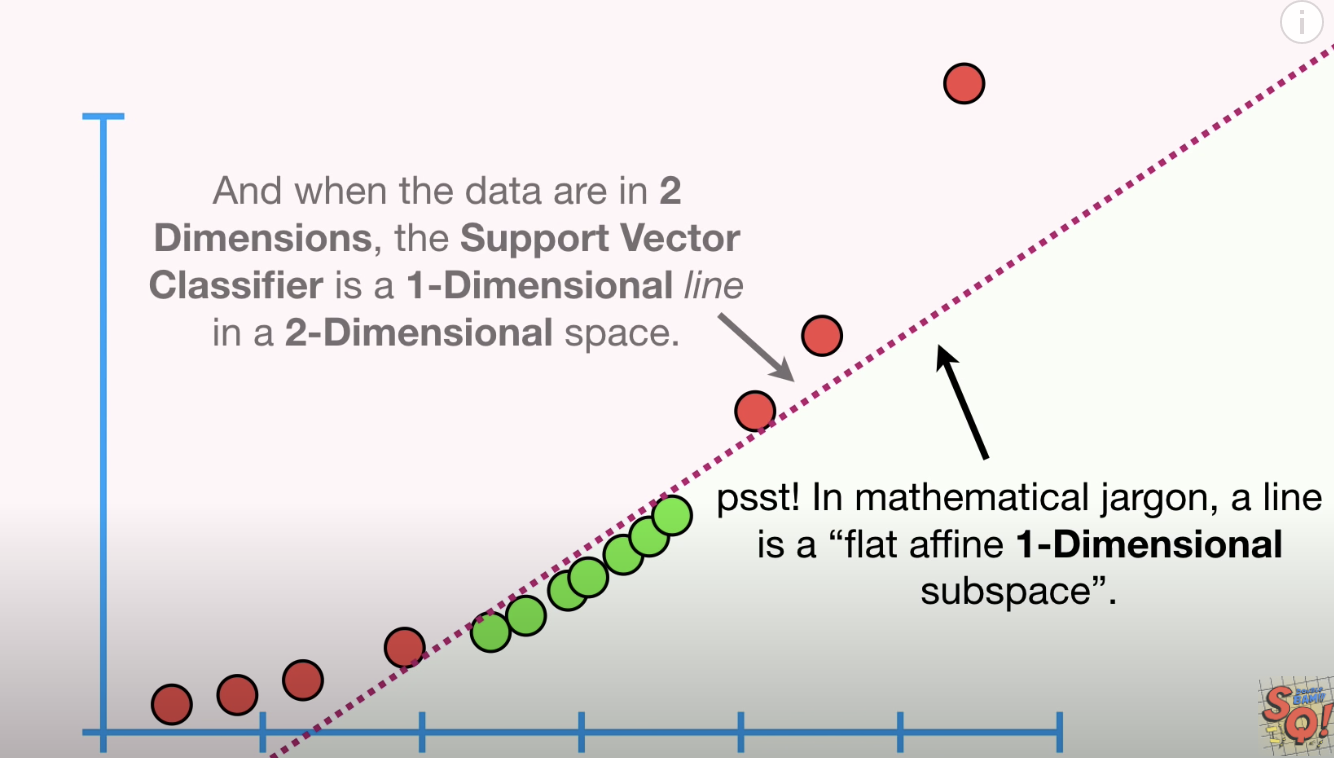
图3-D:
SVM 背后的原理
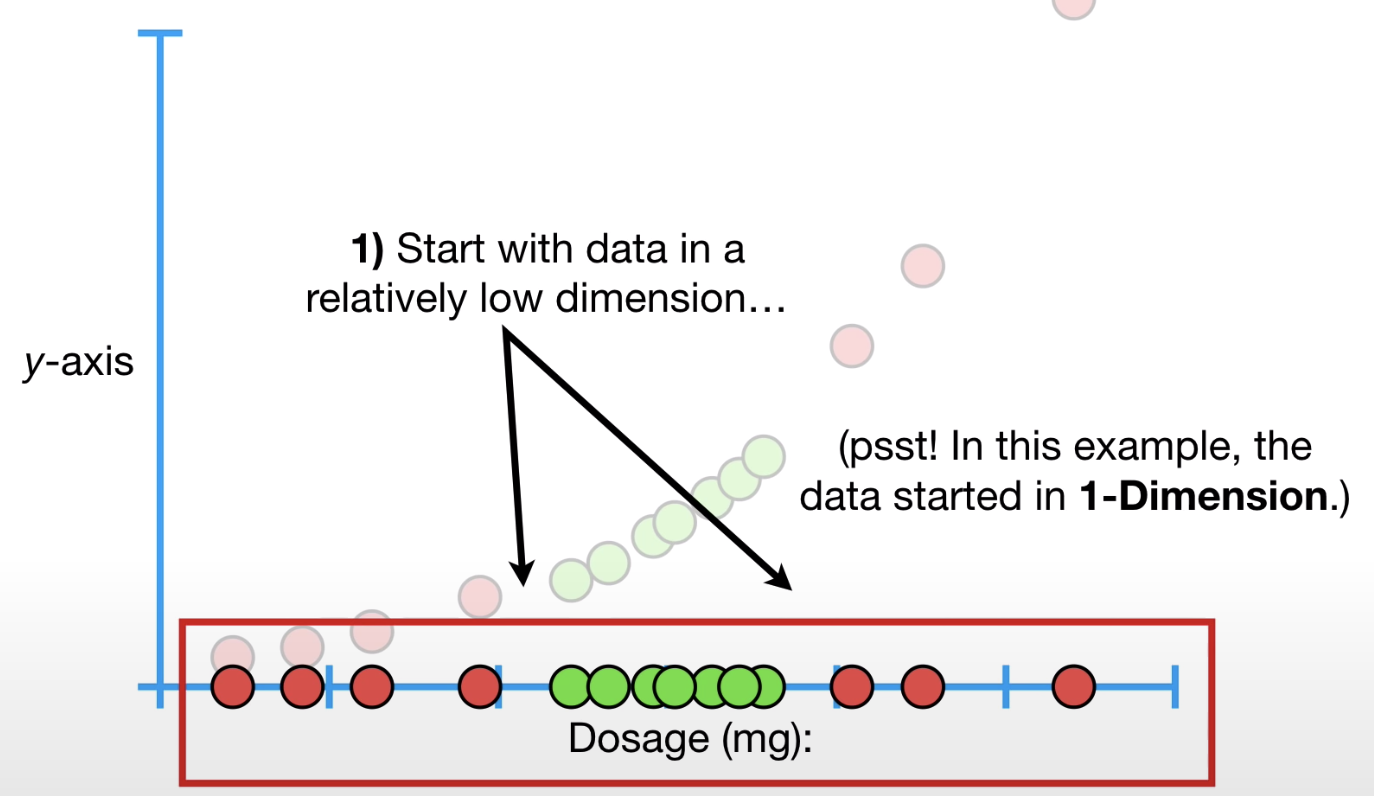
首先以低维数据开始
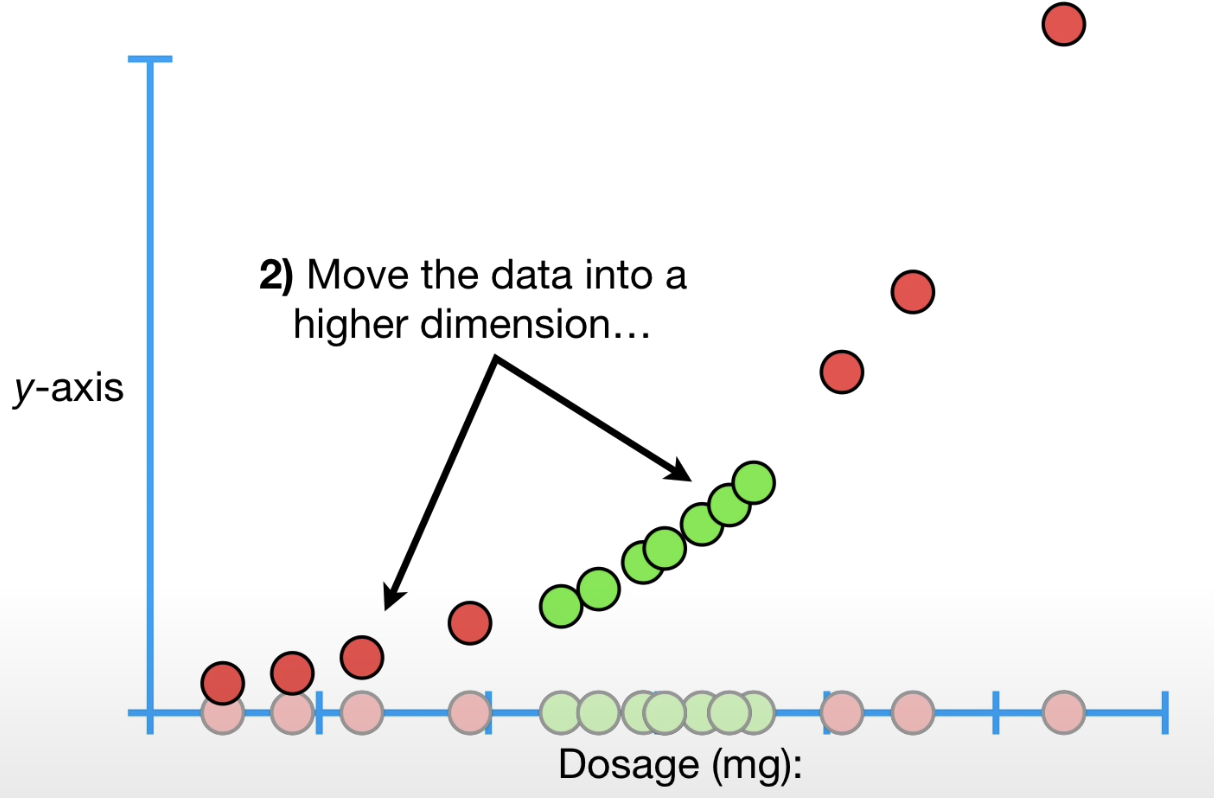
然后将数据转为更高的维度
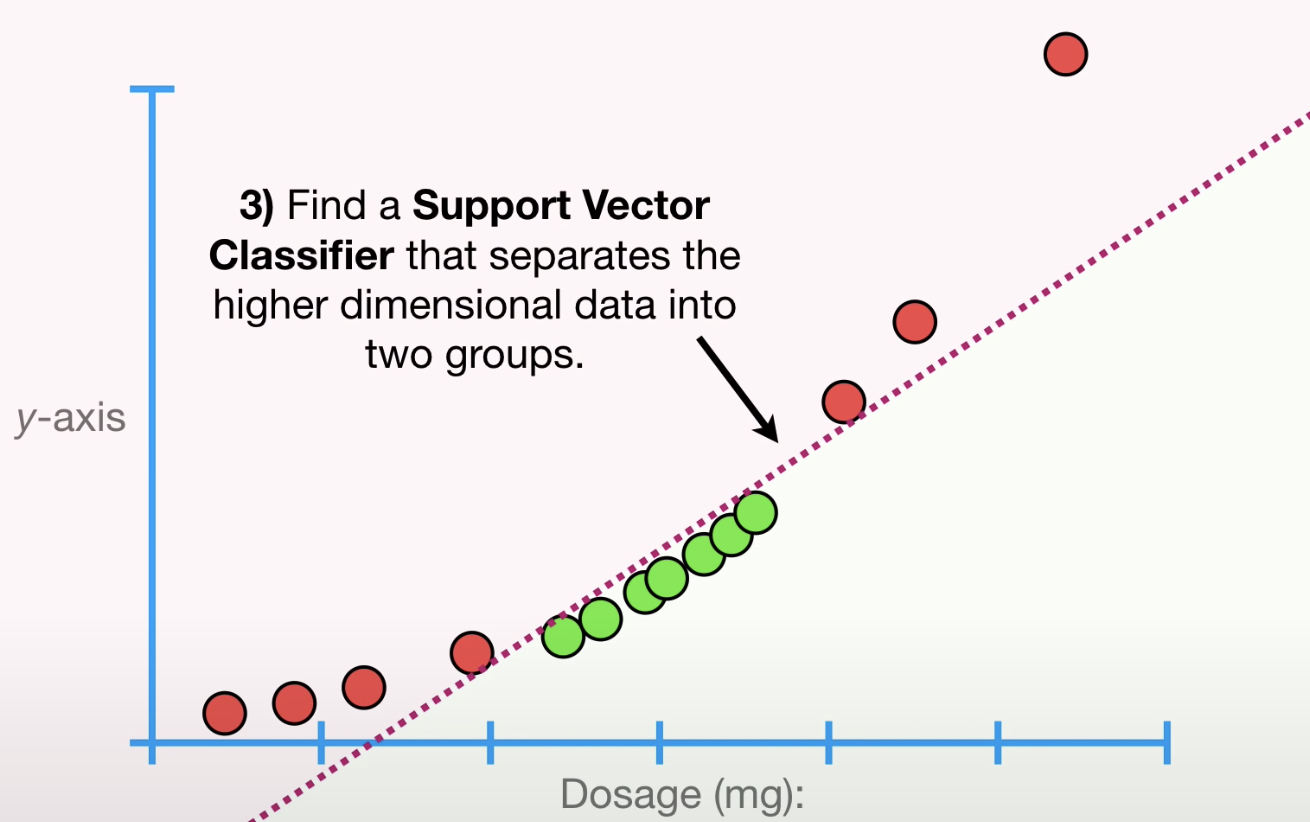
找到一个Support Vector Classifier可以将高维数据分为两类
SVM数学原理
利用核函数(Kernel Functions)找到Support Vector Classifier
- Polynomial Kernel(多项核):包含参数d,表示多项式的维度,如d=1,表示1维,d=3,表示3维。
- Radial Kernel:用于无限维度
SVM优缺点
优点:
- High Dimensionality
- Memory Efficiency
- Versatility
缺点:
- Kernel Parameters Selection
- Non-Probabilistic
R和Python中实现SVM
R中实现SVM
R中可以借助package e1071,
1 | #Import Library |
具体参考:https://www.datacamp.com/community/tutorials/support-vector-machines-r
Python中实现SVM
Python中可以借助scikit-learn库,
1 | #Import Library |
参考资料