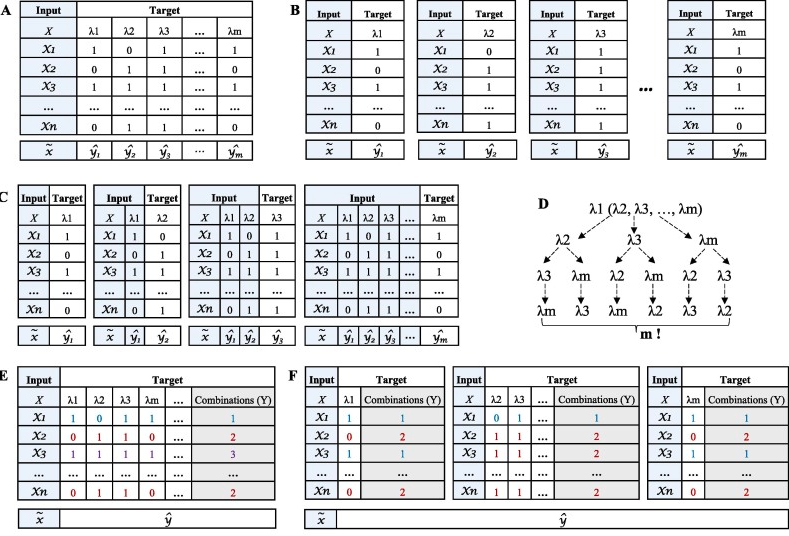
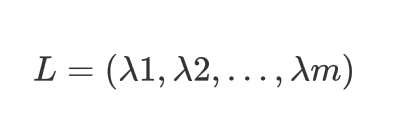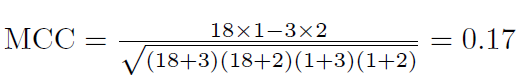今天介绍一篇基于transformer架构对小分子进行探究理解和多任务分析的文章。其中多任务分子分析包括分子特性预测,化学反应分析,药物相互作用的预测,分子从头生成和分子优化。

背景
Transformers
Transformer 是2017年由googleAI 在“Attention Is All You Need”的文章中提出的一个模型,最初主要用于自然语言处理。该模型是基于注意力机制,完全不需要递归和卷积,与传统的自然语言处理常用的RNN或CNN相比,在性能上更胜一筹,同时具有更高的可并行性,并且需要的训练时间也大大减少。
BERT (Bidirectional Encoder Representations from Transformers )
BERT是基于Transformers的双向编码器特征模型,首先对未标记的文本进行深度双向表征的预训练(Pre-training),然后只需增加一个输出层就可以对预训练的BERT模型进行微调(Fine-tuning),从而为广泛的任务(如问题回答和语言推理)创建先进高效的模型,而无需对特定任务的架构进行大量的修改。
课题设计
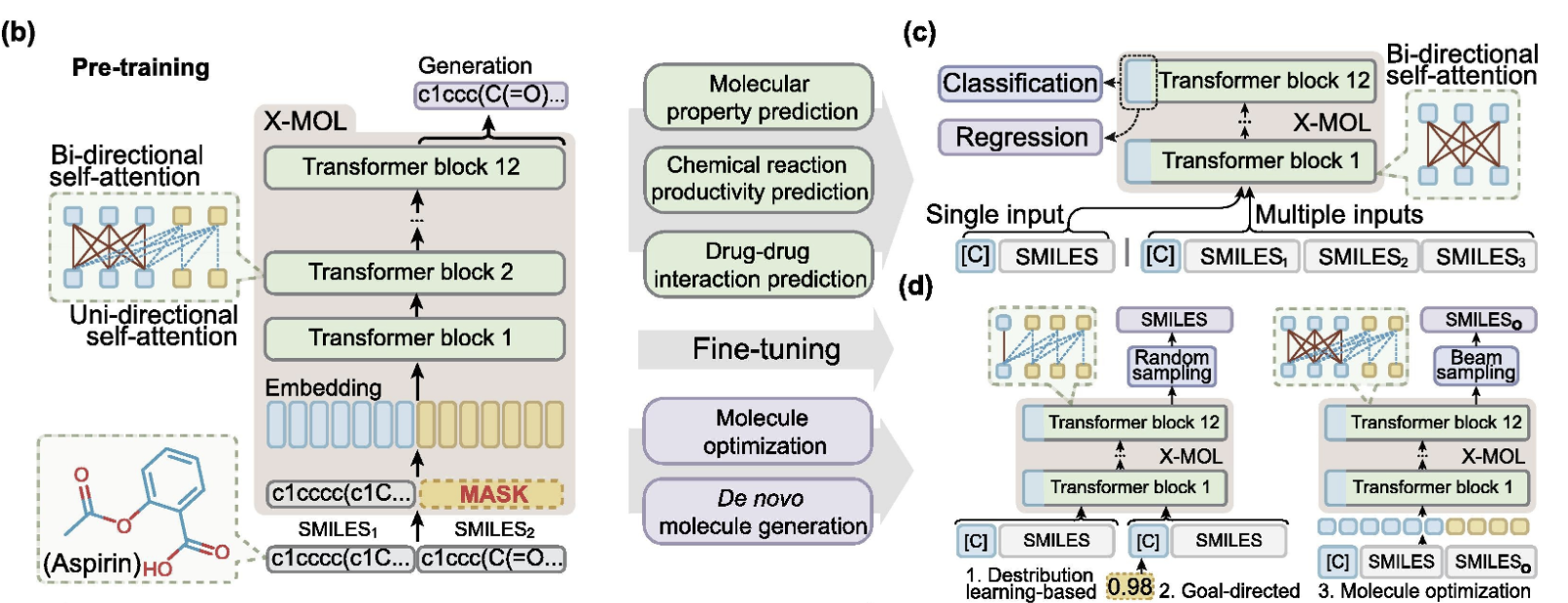
作者在本文中提出了一个模型— X-MOL,也是基于大规模的预训练和微调的架构。首先它使用百度的高性能计算资源对11亿个分子上进行预训练,以SMILES(Simplified Molecular Input Line Entry Specification)为基础,进行分子理解和特征表示。然后使用预训练好的模型,进行不同的微调,以适应不同的下游分子分析任务,包括分子特性预测,化学反应分析,药物相互作用的预测,分子从头生成和分子优化。

具体来说,这里的生成性预训练(generative pre-training)策略是通过一个编码器-解码器架构来实现的。与传统的编码器-解码器架构不同,例如在神经机器翻译中使用的架构,在X-MOL中,编码器和解码器共享多层transformer的参数(图b),迫使编码和解码过程在同一语义空间中进行。在X-MOL中,输入的随机SMILES和输出的随机SMILES被同时送入模型中。同时,输出的随机SMILES被完全掩盖了。此外,只有单向的注意力操作可以在输出的随机SMILES中进行,这意味着输出随机SMILES中的每个字符只能注意自己和先前生成的字符。
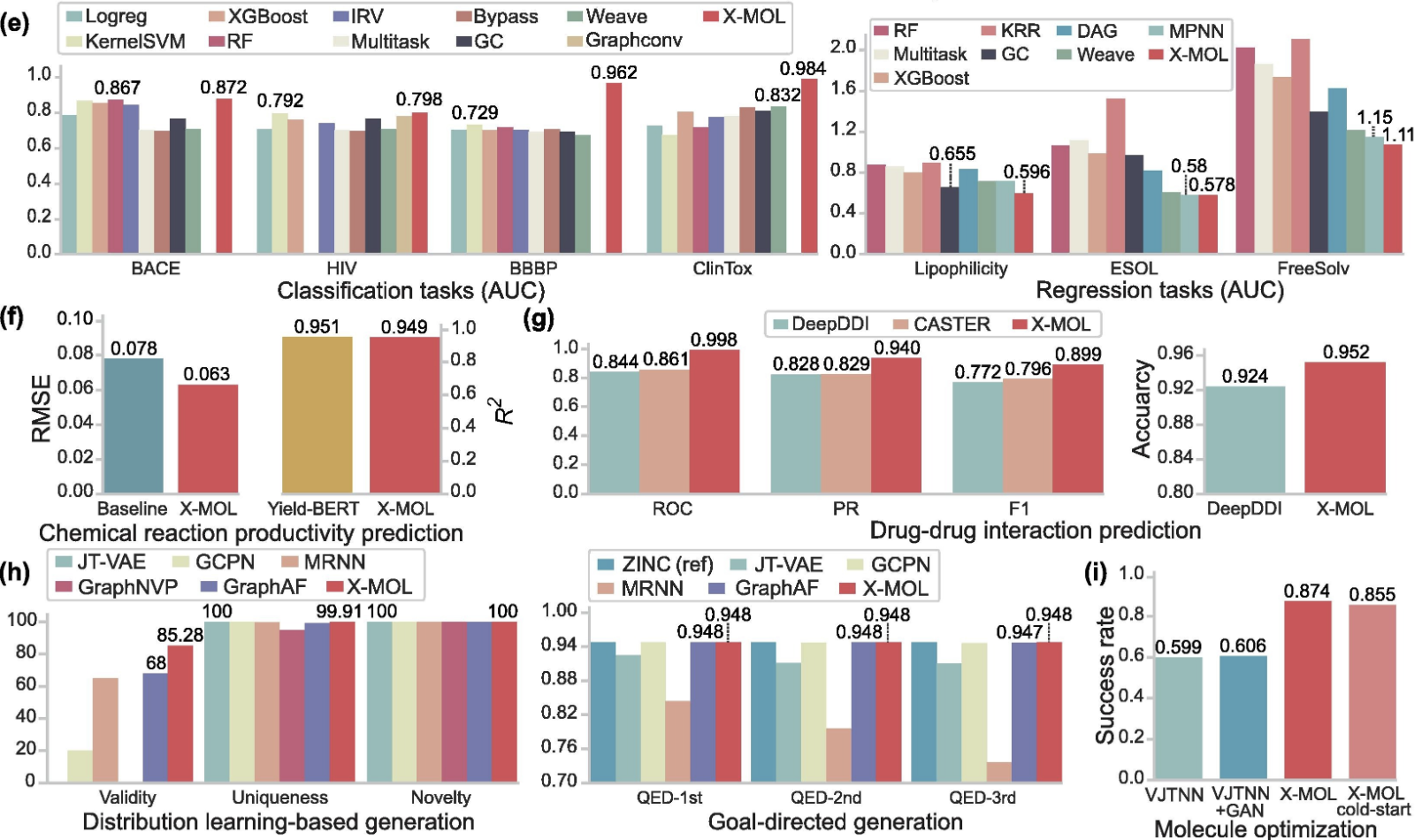
结果
在分子特性预测方面(图e),X-MOL在MoleculeNet基准测试中的分类和回归任务优于现有方法,包括各种经典的浅层学习和深度学习模型。
在化学反应生产率预测方面(图f),X-MOL的RMSE(Root Mean Square Error)也低于基准值。
在药物-药物相互作用预测方面(图g),从ROC,PR, F1,以及准确性上看,X-MOL优于另外两种方法DeepDDI和CASTER。
在分子生成任务方面(图h),X-MOL在基于分布学习的生成中,在有效性、独特性和新颖性这三个测量方面超过了现有的基于图形的分子生成方法。特别是,X-MOL在有效性方面大大超过了其他方法。在目标导向的生成中,X-MOL也优于基于图表示的模型。
在分子优化任务方面(图i),当我们将优化后的分子与原始分子进行比较时,X-MOL和冷启动模型都有助于改善分子优化过程中的目标属性,而且还显示出比VJTNN更好的性能。
文献链接:https://www.sciencedirect.com/science/article/pii/S2095927322000445?via%3Dihub