支持向量机SVM(Support Vector Machines)是监督学习中一类算法,可用于分类、回归和异常值检测。
具体原理可参考 SVM从原理到实现)。R和python都有相关包和模块可以实现SVM,这里讨论如何在python中实现SVM。
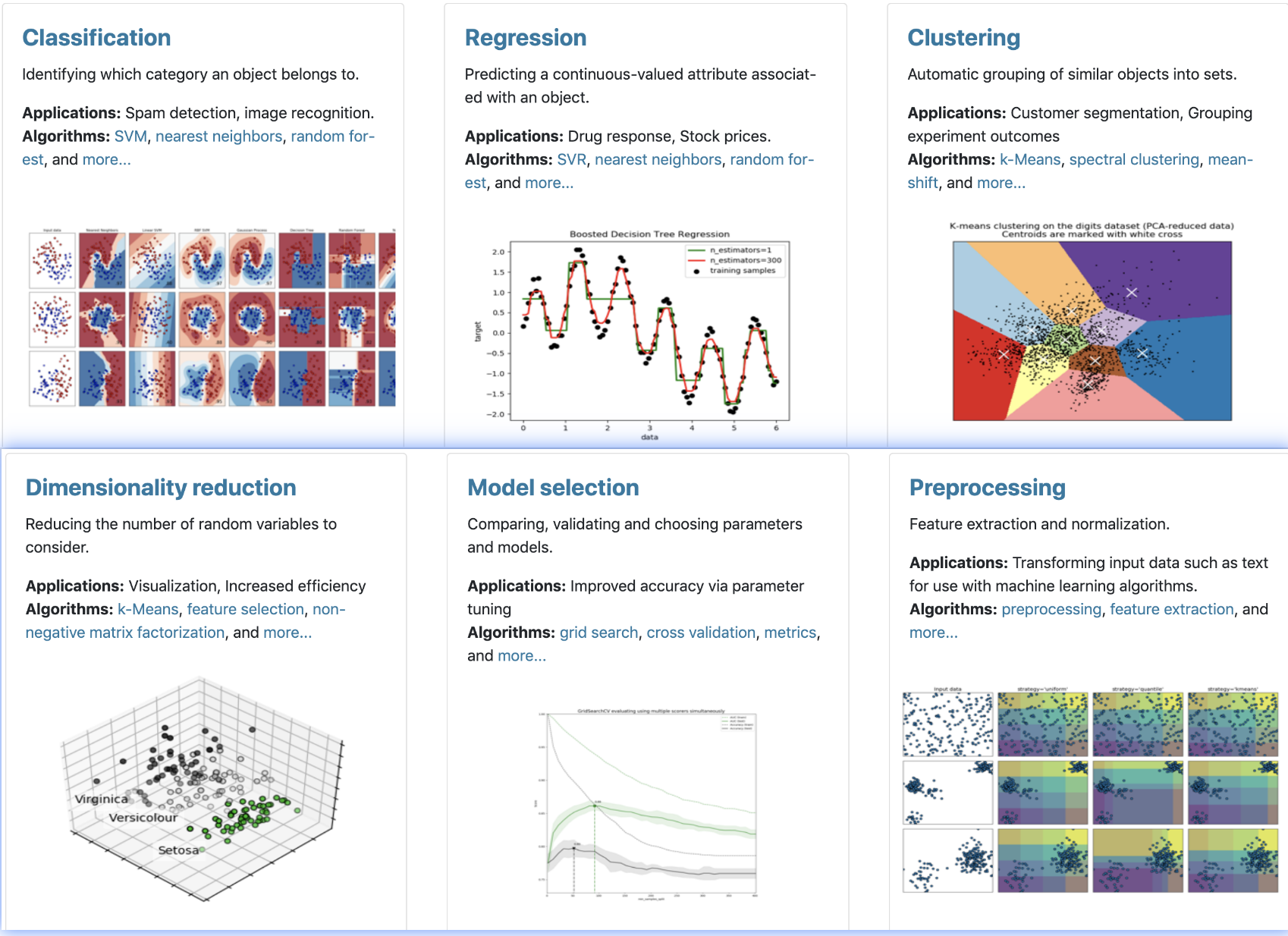
python中是借助于scikit-learn库实现,scikit-learn是python中基于NumPy, SciPy 和matplotlib的一个机器学习库,包含多种功能,可以实现分类、回归、聚类,降维,模型选择和预处理等分析。
安装scikit-learn
1 | pip install -U scikit-learn |
检验是否安装成功
1 | python -m pip show scikit-learn # to see which version and where scikit-learn is installed |
输入数据
scikit learn的输入数据支持密集型向量(包括numpy.ndarray和numpy.asarray)和疏散型向量(任何scipy.sparse)。然而,要使用支持向量机对稀疏数据进行预测,它必须适合此类数据。要获得最佳性能,请使用C-ordered numpy.ndarray(密集)或scipy.sparse.csr_matrix(稀疏),dtype=float64。
输入数据需包括两个数组(array),数组X [n_samples,n_features], 数组Y[n_samples]。
示例数据:bankdata:
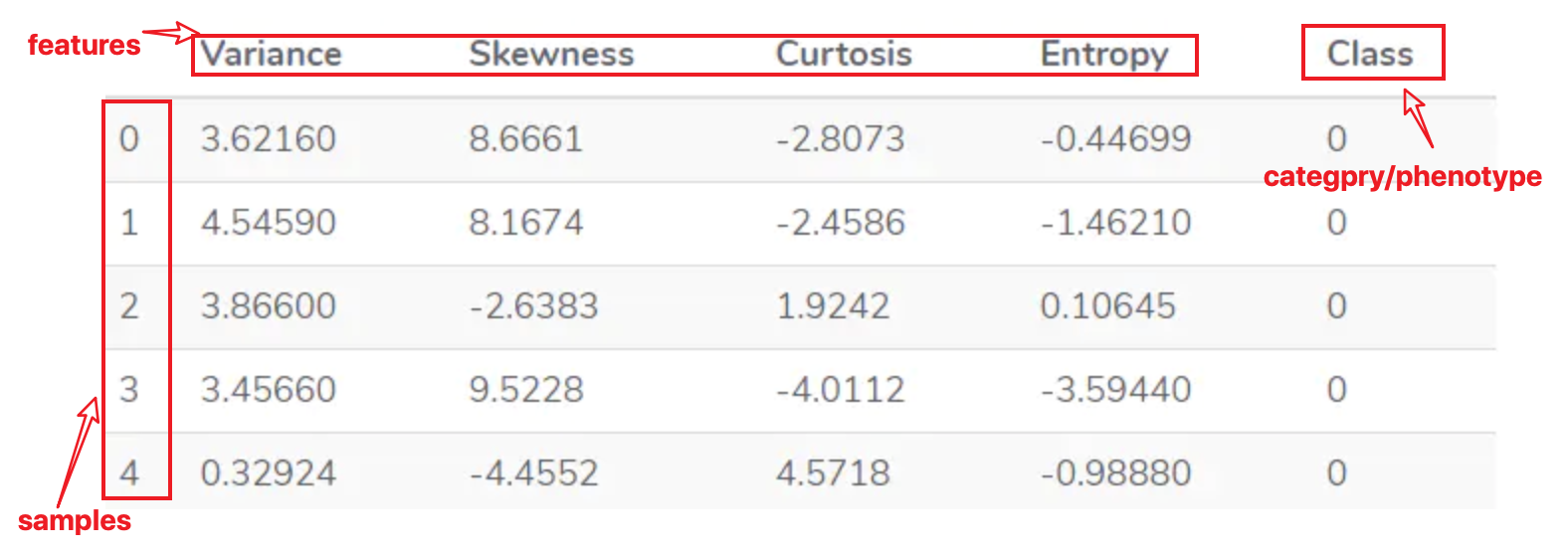
Class为类别,以0,1表示,其他特征值都是数值。
首先把特征属性和类别标签分开,得到初始数据X和y.
1 | X = bankdata.drop('Class', axis=1) |
训练集和测试集的区分
Scikit-Learn中的model_selection模块包含的train_test_split函数可以设置训练集和测试集的分割。
1 | from sklearn import svm |
算法训练
Scikit-Learn中的SVM模块包含SVC, NuSVC以及LinearSVC函数
SVC和NuSVC是相似的方法,但接受的参数集略有不同,并且有不同的数学公式。另一方面,LinearSVC是支持向量分类在线性核情况下的另一种实现。注意,LinearSVC不接受关键字kernel,因为这被假定为线性的。它也缺少SVC和NuSVC的一些成员,比如support_.。
与其他分类器一样,SVC、NuSVC和LinearSVC将两个数组作为输入:一个数组X的大小[n_samples,n_features]包含训练样本,一个数组y的类标签(字符串或整数),大小[n_samples]:
这里以线性为例,把训练数据传给 SVC 类 fit 方法来训练算法
1 | from sklearn.svm import SVC |
预测模型
SVC 类的 predict 方法可以用来预测新的数据的类别
1 | y_pred = svclassifier.predict(X_test) |
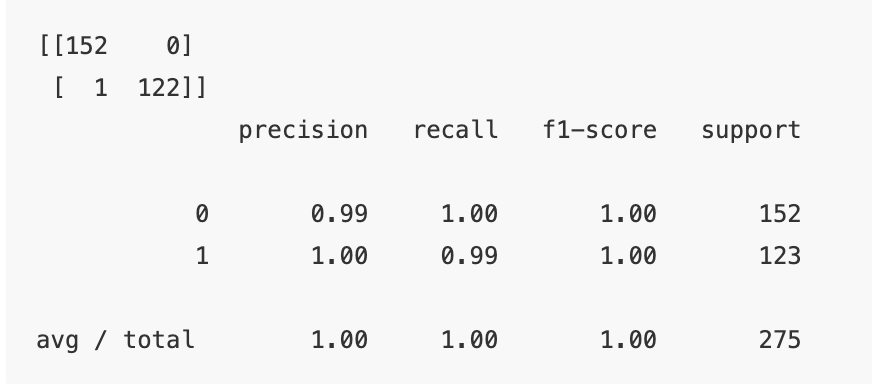
算法评价
精度、召回率和 F1 是分类任务最常用的一些评价指标.Scikit-Learn 的 metrics 模块中提供了 classification_report 和confusion_matrix 等方法,这些方法可以快速的计算这些评价指标.
1 | from sklearn.metrics import classification_report, confusion_matrix |
评价结果